
Outages
Here’s where we post our reports to avoid them happening again.
Latest updates
-
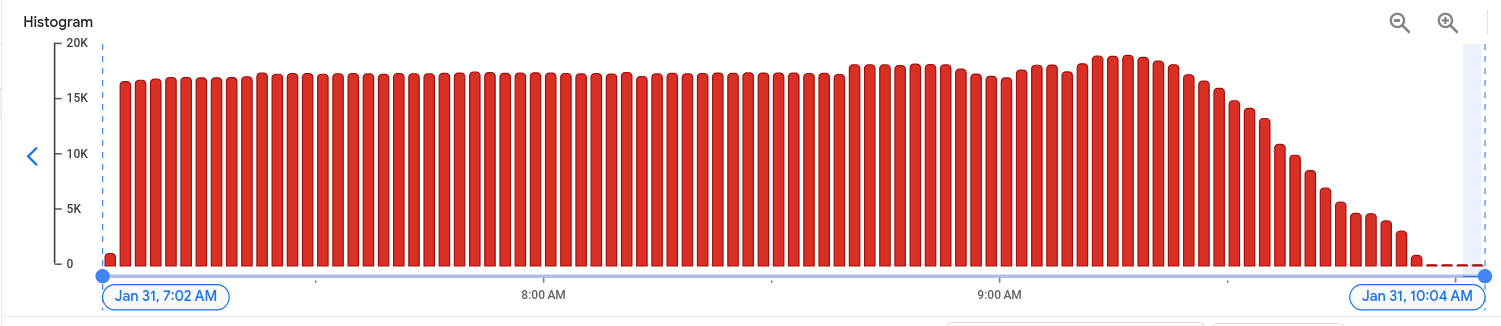
Report: 2024-01 Production Cluster CPU Spike incident
After deducing that it was the new PHP version that introduced our symptoms via the new number of deprecations reported to Sentry, we reduced the polling rate on the WordPress…
-
Report: 2021-09-13 Cloudflare Update error
On Monday 12th of July all Planet 4 sites went down due to an unusual traffic load.
-
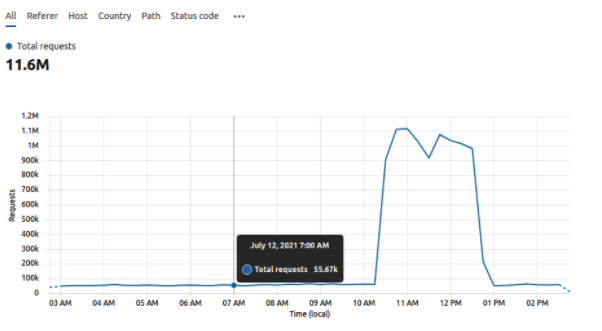
Report: 2021-07-12 DDOS on Landing Page
On Monday 12th of July all Planet 4 sites went down due to an unusual traffic load.
-
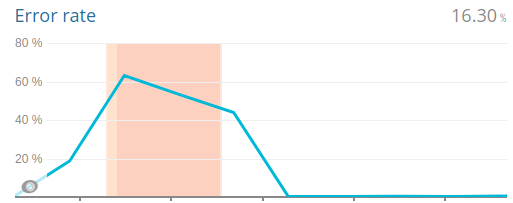
Report: 2021-04-15 DDOS on www.greenpeace.ch
Executive summary: On the night (CET) of Friday 29 of November, we received some alerts, and reports from editors, that specific P4 websites were unresponsive.
-
Report: 2020-08-09 outage on P4 International website
Executive summary: On the night (CET) of Friday 29 of November, we received some alerts, and reports from editors, that specific P4 websites were unresponsive.