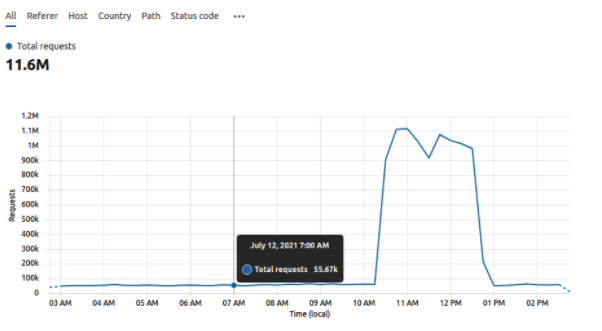
On Monday 12th of July all Planet 4 sites went down due to an unusual traffic load.
Forensic:
Ingress controller (Traefik) was not set to scale
Strengthen protection against automated queries in Cloudflare (set by Loïc)
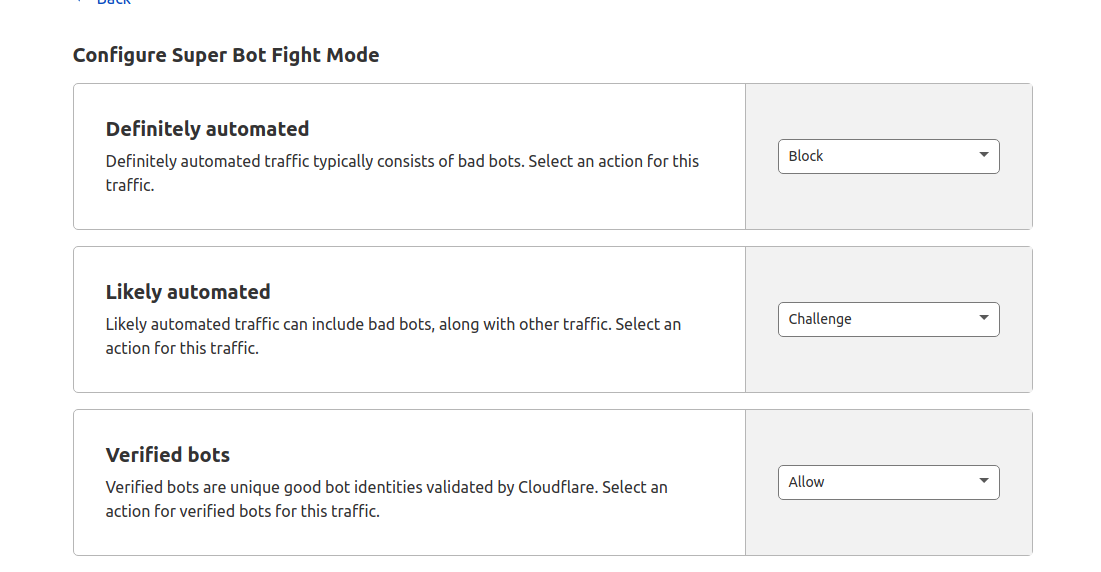
Longer term action to be taken to prevent it to happen again :
- Process to switch from Traefik to Nginx as ingress controller is already planned
- this is pending some action on planification
- Set auto scaling on ingress controller
Post Incident Actions – Sprint 87
Incident description
P4 went down due to an unusual traffic load.
Ingress Control process (Traefik) runs out of memory due to load.

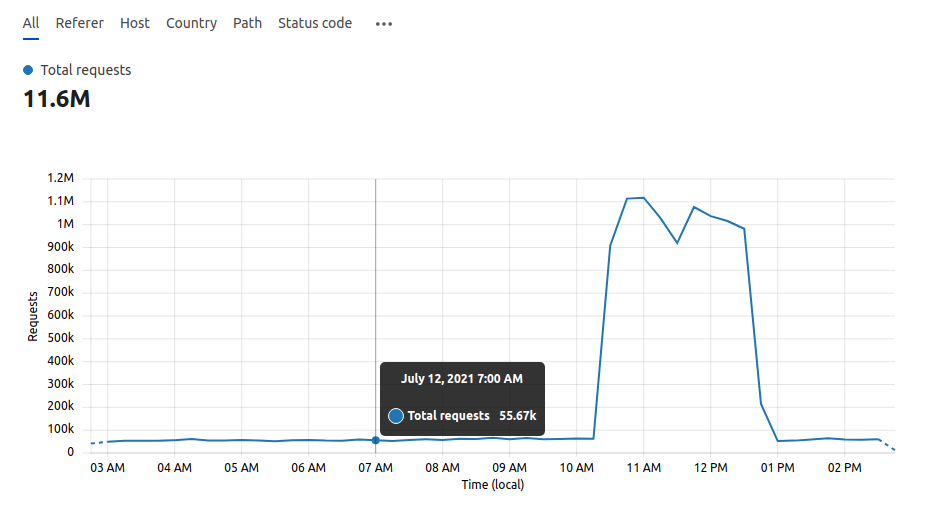
Expected behavior when fixed
P4 up and running.
Traffic load back to normal.
SLO
Not currently applicable for this incident
Communication
Audience : IT-Announcement, web-folks
Last communication : 12 July 2021 – 12:40 UTC
Issue resolved
Minutes
12 July 2021 – 9:20 am UTC
Communication : Currently experiencing problems with our P4 cluster, we are working to resolve this issue ASAP. This affects all our P4 sites. We are upping resources now to our Traefik deployment to sort this out.
12 July 2021 – 9:30 UTC
Action : upped the pods running the traefik service from 3 to 5, will change the max RAM per pod to 1GB from 512mb and continue to monitor the problem.
12 July 2021 – 12:40 UTC
Communication : P4 is back up.
It was down from 11:00 to11:08 for a total of 8 minutes.
We upped the pods running the traefik service from 3 to 5, will change the max RAM per pod to 1GB from 512mb and continue to monitor the problem.
We received unusually high traffic. We have scaled resources to cope but still have a large number of requests and are looking at mitigation.